

Sankcijos nepadėjo: Kinijos bendrovės Z.ai dirbtinio intelekto modelis užėmė lyderio pozicijas reitinguose
Kinijos bendrovė Z.ai pristatė DI modelį GLM-5.2, kuris iš karto užėmė pirmąją vietą „Artificial Analysis“ indekse. Visa GLM-5 modelių šeima buvo apmokyta išskirtinai naudojant Huawei Ascend 910B procesorius, o Nvidia įranga nebuvo naudojama. Kol JAV bando apriboti prieigą prie galingiausių uždarų modelių Fable 5 ir Mythos 5, Kinija išleidžia atvirojo kodo modelį, kurį galima atsisiųsti ir paleisti lokaliai.
Birželio 17 d. Z.ai paskelbė oficialius GLM-5.2 testų rezultatus, taip pat pagal MIT licencijuotus modelius, skirtus Hugging Face platformai. Šie rodikliai leidžia GLM-5.2 užimti iš tiesų konkurencingą poziciją lyginant su uždarais Vakarų modeliais. Code Arena reitingų lentelėje, paremtoje aklu žmonių balsavimu poromis, GLM-5.2 užėmė antrą vietą bendroje įskaitoje, surinkusi 1595 balus, ir pirmą vietą tarp viešai prieinamų modelių, nes Fable 5 buvo pašalinta iš Arena atrankos po eksporto draudimo.
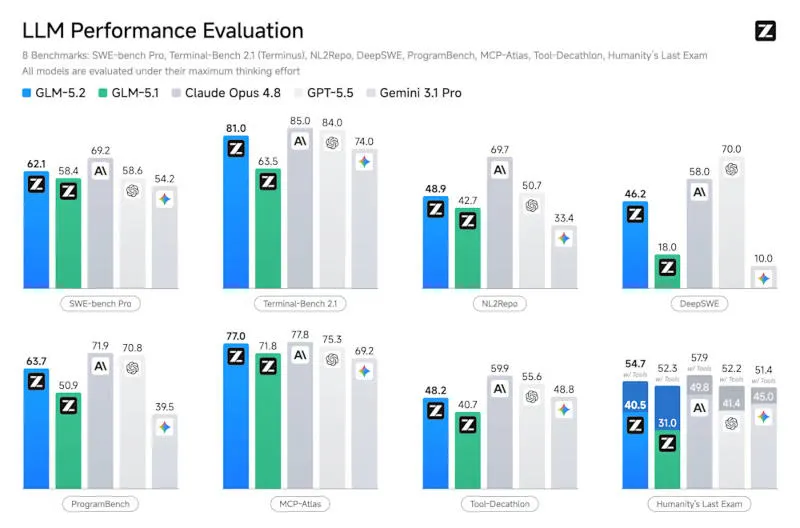
SWE-bench Pro – realiame GitHub problemų sprendimo teste – GLM-5.2 surinko 62,1 balo ir aplenkė OpenAI GPT-5.5, kuris surinko 58,6 balo. Design Arena reitinge GLM-5.2 užėmė pirmąją vietą. Tačiau SWE-Marathon – reikliausiame agentinio programavimo vertinimo teste su ilgalaikėmis užduotimis – GLM-5.2 surinko tik 13,0 balo, palyginti su 26,0 balais, kuriuos pasiekė Claude Opus 4.8.
Remiantis 2026 m. Stanfordo universiteto DI indeksu, bendras našumo atotrūkis tarp geriausių JAV ir Kinijos DI modelių sumažėjo iki 2,7 procentinio punkto, tačiau JAV modeliai vis dar išlaiko pranašumą sudėtingiausiose loginio mąstymo užduotyse, sukurtose specialiai tam, kad būtų išvengta manipuliavimo rezultatais.
GLM-5.2 naudoja „ekspertų mišinio“ (Mixture-of-Experts, MoE) architektūrą su 744 mlrd. parametrų, iš kurių kiekvienam atsakymui naudojama maždaug 40 mlrd. Maršrutizavimo mechanizmas kiekvienam tokenui parenka 8 iš 256 specializuotų ekspertinių posistemių, o likusios lieka neaktyvios. Tai leidžia modeliui išlaikyti pažangias galimybes nemokant visos skaičiavimo kainos kiekvienos užklausos metu.
Svarbiausia architektūrinė savybė darbui su ilgais kontekstais yra integruotas retinto dėmesio mechanizmas (DeepSeek Sparse Attention, DSA). Vietoj pilno kvadratinio dėmesio skaičiavimo visiems tokenams konteksto lange, kuris tampa nepakeliamai brangus pasiekus milijoną tokenų, DSA selektyviai kreipia dėmesį tik į svarbiausius tokenus. Tai leidžia 1 mln. tokenų konteksto langą naudoti praktiškai, o ne tik teoriškai, ir būtent DSA suteikia GLM-5.2 galimybę vienu inferencijos ciklu apdoroti visą didelį programinį kodą.
Huawei Ascend mokymo infrastruktūros kompromisai yra akivaizdūs. GLM-5.2 generuoja maždaug 17–19 tokenų per sekundę, o konkurentai, naudojantys Nvidia lustus, pasiekia 25–30 ir daugiau tokenų per sekundę. Šis pralaidumo skirtumas atspindi tiek MoE maršrutizavimo sąnaudas, tiek mažesnį Ascend įrangos lustų našumą, palyginti su Nvidia H100 klasės procesoriais.
GLM-5.2 mokymas pareikalavo maždaug 15 % daugiau skaičiavimo laiko nei analogiški mokymai naudojant Nvidia lustus. Ekspertų vertinimu, mokymo procesas kainavo apie 25 mln. JAV dolerių, o tai yra gerokai mažiau nei panašių pažangiausių JAV modelių mokymo išlaidos. Tai tapo įmanoma dėl santykinai mažos Ascend lustų kainos ir Kinijos vyriausybės subsidijų.

Priartėjimas prie etaloninių rezultatų ir realus naudingumas nėra tas pats. Sudėtingiausiuose ARC-AGI-2 testuose, kurie tikrina naują ir lankstų mąstymą, o ne išmoktus šablonus, pažangiausi Kinijos modeliai vis dar pastebimai nusileidžia JAV modeliams. Epoch AI ekspertų vertinimu, atsilikimas sudaro vidutiniškai septynis mėnesius visame pažangių galimybių indekse. Nepaisant to, GLM-5.2 etaloninių rodiklių paritetą pasiekė greičiau, nei tikėjosi nepriklausomi stebėtojai.
Argumentas už pažangių JAV modelių eksporto kontrolę iš dalies grindžiamas prielaida, kad Kinijos laboratorijos smarkiai atsilieka pažangių technologijų įsisavinimo srityje. Tačiau jei Kinijos modelis iki 2026 m. pabaigos pademonstruos pagrindinių komercinių Fable galimybių lygį, gali kilti pagrįstų abejonių dėl JAV vyriausybės nustatytų apribojimų veiksmingumo.
Hugging Face paskelbti GLM-5.2 modelio svoriai iš tiesų yra nemokami: MIT licencija, jokių naudojimo apribojimų, jokių regioninių blokavimų ir jokios galimybės bet kuriai vyriausybei panaikinti prieigą po atsisiuntimo. Kūrėjas, talpinantis GLM-5.2 savo infrastruktūroje, yra apsaugotas tiek nuo JAV eksporto apribojimų, tiek nuo Kinijos vyriausybės prieigos prie duomenų. Savarankiškas modelio talpinimas pašalina duomenų nutekėjimo per API riziką, tačiau reikalauja apie 1,5 TB vaizdo procesorių atminties, todėl yra sunkiai prieinamas komandoms, neturinčioms korporacinio masto infrastruktūros.
Tačiau debesų API yra visai kas kita. Z.ai yra Pekine registruota ir pagal Kinijos įstatymus veikianti bendrovė. Kinijos Nacionalinės žvalgybos įstatymas reikalauja, kad visos Kinijos organizacijos ir piliečiai „remtų, padėtų ir bendradarbiautų vykdant valstybės žvalgybos veiklą“. Duomenų saugumo įstatymas ir Kibernetinio saugumo įstatymas numato papildomas nuostatas dėl duomenų lokalizavimo ir vyriausybės prieigos. Tai yra fiksuotos teisinės sąlygos, galiojančios nepriklausomai nuo Z.ai deklaruojamos privatumo politikos ar jos serverių fizinės vietos.
2025 m. sausį JAV Pramonės ir saugumo biuras įtraukė Z.ai į sankcijų sąrašą, nurodydamas bendrovės vaidmenį skatinant Kinijos kariuomenės modernizaciją per DI kūrimą. 2026 m. gegužę JAV Atstovų Rūmų įstatymų leidėjai pradėjo oficialų tyrimą dėl kibernetinio saugumo rizikų, susijusių su Kinijos DI modeliais kritinėje infrastruktūroje, o Z.ai pateko tarp bendrovių, kurioms skiriamas ypatingas dėmesys.
JAV vyriausybė nuo 2022 m. spalio nuosekliai griežtino DI lustų eksporto kontrolę, siekdama apriboti Kinijos prieigą prie pažangių technologijų ir sulėtinti Kinijos DI plėtrą. GLM-5 modelių šeima, apmokyta naudojant 100 000 Huawei Ascend 910B lustų be jokio Nvidia dalyvavimo, rodo visiškai priešingą šių veiksmų rezultatą.